
Introduction
Apache Synapse loads its configuration from a set of XML files. This enables the user to easily hand edit the configuration, maintain backups and even include the entire configuration in a version control system for easier management and control. For an example one may check-in all Synapse configuration files into a version control system such as Subversion and easily move the configuration files from development, through QA, staging and into production.
All the configuration files related to Synapse are housed in the repository/conf/synapse-config directory of the Synapse installation. Synapse is also capable of loading certain configuration elements (eg: sequences, endpoints) from an external SOA registry. When using a registry to store fragments of the configuration, some configuration elements such as endpoints can be updated dynamically while Synapse is executing.
This article describes the hierarchy of XML files from which Synapse reads its configuration. It describes the high level structure of the file set and the XML syntax used to configure various elements in Synapse.
Contents
- Synapse Configuration
- Functional Components Overview
- Synapse Configuration Files
- Configuration Syntax
- Registry Configuration
- Local Entry (Local Registry) Configuration
- Sequence Configuration
- Endpoint Configuration
- Proxy Service Configuration
- Scheduled Task Configuration
- Template Configuration
- Event Source Configuration
- API Configuration
- Priority Executor Configuration
- Message Stores and Processors Configuration
The Synapse Configuration
A typical Synapse configuration is comprised of sequences, endpoints, proxy services and local entries. In certain advanced scenarios, Synapse configuration may also contain scheduled tasks, event sources, messages stores and priority executors. Synapse configuration may also include a registry adapter through which the mediation engine can import various resources to the mediation engine at runtime. Following diagram illustrates different functional components of Synapse and how they interact with each other.
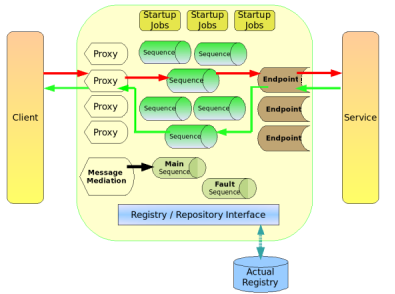
All the functional components of the Synapse configuration are configured through XML files. The Synapse configuration language governs the XML syntax used to define and configure different types of components. This configuration language is now available as a XML schema.
Typically the Synapse ESB is used to mediate the message flow between a client and a back-end service implementation. Therefore Synapse can accept a message on behalf of the actual service and perform a variety of mediation tasks on it such as authentication, validation, transformation, logging and routing. Synapse can also detect timeouts and other communication errors when connecting to back-end services. In addition to that users can configure Synapse to perform load balancing, access throttling and response caching. In case of a fault scenario, such as an authentication failure or a schema validation failure, the Synapse ESB can be configured to return a custom message or a SOAP fault to the requesting client without forwarding the message to the back-end service. All these scenarios and use cases can be put into action by selecting the right set of functional components of Synapse and combining them appropriately through the Synapse configuration.
Depending on how functional components are used in the Synapse configuration, Synapse can execute in one or more of the following operational modes.
Service Mediation (Proxy Services)
In service mediation, the Synapse ESB exposes a service endpoint on the ESB, which accepts messages from clients. Typically these services acts as proxies for existing (external) services, and the role of Synapse would be to 'mediate' these messages before they are delivered to the actual service. In this mode, Synapse could expose a service already available in one transport, over a different transport; or expose a service that uses one schema or WSDL as a service that uses a different schema or WSDL. A Proxy service could define the transports over which the service is exposed, and point to the mediation sequences that should be used to process request and response messages. A proxy service maybe a SOAP or a REST/POX service over HTTP/S or SOAP, POX, plain text or binary/legacy service for other transports such as JMS and VFS file systems.
Message Mediation
In message mediation, Synapse acts as a transparent proxy for clients. This way, Synapse could be configured to filter all the messages on a network for logging, access control etc, and could 'mediate' messages without the explicit knowledge of the original client. If Synapse receives a message that is not accepted by any proxy service, that message is handled through message mediation. Message mediation always processes messages according to the mediation sequence defined with the name 'main'.
Task Scheduling
In task scheduling, Synapse can execute a predefined task (job) based on a user specified schedule. This way a task can be configured to run exactly once or multiple times with fixed intervals. The schedule can be defined by specifying the number of times the task should be executed and the interval between executions. Alternatively one may use the Unix Cron syntax to define task schedules. This mode of operation can be used to periodically invoke a given service, poll databases and execute other periodic maintenance activities.
Eventing
In eventing mode, Synapse can be used as an event source and users or systems can subscribe to receive events from Synapse. Synapse can also act as an event broker which receives events from other systems and delivers them to the appropriate subscribers with or without mediation. The set of subscribers will be selected by applying a predefined filter criteria. This mode enables Synapse to integrate applications and systems based on the Event Driven Architecture (EDA).
Functional Components Overview
As described in the previous section, Synapse engine is comprised of a range of functional components. Synapse configuration language is used to define, configure and combine these components so various messaging scenarios and integration patterns can be realized. Before diving into the specifics of the configuration language, it is useful to have a thorough understanding of all the functional components available, their capabilities and features. A good knowledge on Synapse functional components will help you determine which components should be used to implement any given scenario or use case. In turns it will allow you to develop powerful and efficient Synapse configurations thus putting the ESB to maximum use.
As of now Synapse mediation engine consists of following functional elements:
- Mediators and sequences
- Endpoints
- Proxy services
- Scheduled tasks
- Event sources
- Sequence templates
- Endpoint templates
- Registry adapter
- APIs
- Priority executors
- Message stores and processors
Mediators and Sequences
The Synapse ESB defines a 'mediator' as a component which performs a predefined action on a message during a message flow. It is the most fundamental message processing unit in Synapse. A mediator can be thought of as a filter that resides in a message flow, which processes all the messages passing through it.
A mediator gets full access to the messages at the point where it is defined. Thus they can inspect, validate and modify messages. Further, mediators can take external action such as looking up a database or invoking a remote service, depending on some attributes or values in the current message. Synapse ships with a variety of built-in mediators which are capable of handling an array of heterogeneous tasks. There are built-in mediators that can log the requests, perform content transformations, filter out traffic and a plethora of other messaging and integration activities.
Synapse also provides an API using which custom mediators can be implemented easily in Java. The 'Class' and 'POJO (command)' mediators allow one to plugin a Java class into Synapse with minimal effort. In addition, the 'Script' mediator allows one to provide an Apache BSF script (eg: JavaScript, Ruby, Groovy etc) for mediation.
A mediation sequence, commonly called a 'sequence' is a list of mediators. A sequence may be named for re-use, or defined in-line or anonymously within a configuration. Sequences may be defined within the Synapse configuration or in the Registry. From an ESB point of view, a sequence equates to a message flow. It can be thought of as a pipe consisting of many filters, where individual mediators play the role of the filters.
A Synapse configuration contains two special sequences named 'main' and 'fault'. These too may be defined in the Synapse configuration, or externally in the Registry. If either is not found, a suitable default configuration is generated at runtime by the ESB. The default 'main' sequence will simply send a message without any mediation, while the default 'fault' sequence would log the message and error details and stop further processing. The 'fault' sequence executes whenever Synapse itself encounters an error while processing a message, or when a fault handler has not been defined to handle exceptions. A sequence can assign another named sequence as its 'fault' handler sequence, and handover control to the fault handler if an error is encountered during the execution of the initial sequence.
Endpoints
An Endpoint definition within Synapse defines an external service endpoint and any attributes or semantics that should be followed when communicating with that endpoint. An endpoint definition can be named for re-use, or defined in-line or anonymously within a configuration. Typically an endpoint would be based on a service address or a WSDL. Additionally the Synapse ESB supports Failover and Load-balance endpoints - which are defined over a group of endpoints. Endpoints may be defined within the local Synapse configuration or within the Registry.
From a more practical stand point, an endpoint can be used to represent any entity to which Synapse can make a connection. An endpoint may represent a URL, a mail box, a JMS queue or a TCP socket. The 'send' mediator of Synapse which is used to forward messages can take an endpoint as an argument. In that case the 'send' mediator would forward the message to the specified endpoint.
Proxy Services
A proxy service is a virtual service exposed on Synapse. For the external clients, a proxy service looks like a full fledged web service which has a set of endpoint references (EPRs), a WSDL and a set of developer specified policies. But in reality, a proxy service sits in front of a real web service implementation, acting as a proxy, mediating messages back and forth. The actual business logic of the service resides in the real back-end web service. Proxy service simply hides the real service from the consumer and provides an interface through which the actual service can be reached but with some added mediation/routing logic.
Proxy services have many use cases. A proxy can be used to expose an existing service over a different protocol or a schema. The mediation logic in the proxy can take care of performing the necessary content transformations and protocol switching. A proxy service can act as a load balancer or a lightweight process manager thereby hiding multiple back-end services from the client. Proxy services also provide a convenient way of extending existing web services without changing the back-end service implementations. For an example a proxy service can add logging and validation capabilities to an existing service without the developer having to implement such functionality at service level. Another very common usage of proxy services is to secure an existing service or a legacy system.
A proxy service is a composite functional component. It is made of several sequences and endpoints. Typically a proxy service consists of an 'in sequence', an 'out sequence' and an endpoint. The 'in sequence' handles all the incoming requests sent by the client. Mediated messages are then forwarded to the target endpoint which generally points to the real back-end service. Responses coming back from the back-end service are processed by the 'out sequence'. In addition to these a 'fault sequence' can also be associated with a proxy service which is invoked in case of an error.
In addition to the above basic configuration elements, a proxy service can also define a WSDL file to be published, a set of policies and various other parameters.
Scheduled Tasks
A scheduled task is a job deployed in the Synapse runtime for periodic execution. Users can program the jobs using the task API (Java) provided by Synapse. Once deployed, tasks can be configured to run periodically. The execution schedule can be configured by specifying the delay between successive executions or using the Unix Cron syntax.
Templates
A Template is an abstract concept in synapse. One way to view a template, is as a prototype or a function. Templates try to minimize redundancy in synapse artifacts (ie sequences and endpoints) by creating prototypes that users can re-use and utilize as and when needed. This is very much analogous to classes and instances of classes whereas, a template is a class that can be used to wield instance objects such as sequences and endpoints.
Templates is an ideal way to improve re-usability and readability of ESB configurations (XML). Addition to that users can utilize predefined templates that reflect commonly used EIP patterns for rapid development of ESB message/mediation flows.There are two flavours of templates which are Endpoint and Sequence Templates.
An endpoint template is an abstract definition of a synapse endpoint. Users have to invoke this kind of a template using a special template endpoint. Endpoint templates can specify various commons parameters of an endpoint that can be reused across many endpoint definitions (eg: address uri, timeouts, error codes etc).
A sequence template defines a functional form of an ESB sequence. Sequence templates have the ability to parametrize a sequence flow. Generally parametrization is in the form of static values as well as xpath expressions. Users can invoke a template of this kind with a mediator named 'call-template' by passing in the required parameter values.
Remote Registry and Local Registry (Local Entries)
Synapse configuration can refer to an external registry/repository for resources such as WSDLs, schemas, scripts, XSLT and XQuery transformations etc. One or more remote registries may be hidden or merged behind a local registry interface defined in the Synapse configuration. Resources from an external registry are looked up using 'keys' - which are known to the external registry. The Synapse ESB ships with a simple URL based registry implementation that uses the file system for storage of resources, and URLs or fragments as 'keys'.
A registry may define a duration for which a resource served may be cached by the Synapse runtime. If such a duration is specified, the Synapse ESB is capable of refreshing the resource after cache expiry to support dynamic re-loading of resources at runtime. Optionally, a configuration could define certain 'keys' to map to locally defined entities. These entities may refer to a source URL or file, or may be defined as in-line XML or text within the configuration itself. If a registry contains a resource whose 'key' matches the key of a locally defined entry, the local entry shadows the resource available in the registry. Thus it is possible to override registry resources locally from within the configuration. To integrate Synapse with a custom/new registry, one needs to implement the org.apache.synapse.registry.Registry interface to suit the actual registry being used.
APIs
An API is similar to a web application deployed in Synapse. It provides a convenient approach for filtering and processing HTTP traffic (specially RESTful invocations) through the service bus. Each API is anchored at a user defined URL context (eg: /ws) and can handle all the HTTP requests that fall within that context. Each API is also comprised of one or more resources. Resources contain the mediation logic for processing requests and responses. Resources can also be associated with a set of HTTP methods and header values. For an example one may define an API with two resources, where one resources is used to handle GET requests and the other is used to handle POST requests. Similarly an API can be defined with separate resources for handling XML and JSON content (by looking at the Content-type HTTP header).
Resources bare a strong resemblance to proxy services. Similar to proxy services, a resource can also define an 'in sequence', an 'out sequence' and a 'fault sequence'. Just like in the case of proxy services, the 'in sequence' is used to process incoming requests and the 'out sequence' is used to mediate responses.
APIs provide a powerful framework using which comprehensive REST APIs can be constructed on existing systems. For an example a set of SOAP services can be hidden behind an API defined in Synapse. Clients can access the API in Synapse by making pure RESTful invocations over HTTP. Synapse takes care of transforming the requests and routing them to appropriate back-end services which may or may not be based on REST.
Priority Executors
Priority executors can be used to execute sequences with a given priority. Priority executors are used in high load scenarios where user wants to execute different sequences at different priority levels. This allows user to control the resources allocated to executing sequences and prevent high priority messages from getting delayed and dropped. A priority has a specific meaning compared to other priorities specified. For example if we have two priorities with value 10 and 1, messages with priority 10 will get 10 times more resources than messages with priority 1.
Message Stores and Processors
Message store acts as a unit of storage for messages/data exchanged during synapse runtime. By default synapse ships with a in-memory message store and the storage can be plugged in depending on the requirement. There is a specific mediator called store mediator which is able to direct message traffic to a particular message store at runtime.
On the other hand a Message processor has the ability to connect to a message store and perform message mediation or required data manipulations. Essentially a particular message processor will be coupled with a message store and as a result respective message processor will be inherited with the traits of that particular message storage.
For example in the eye of a message processor, data/messages coming from in-memory message store will be seen as more volatile compared to a persistent message store. Nevertheless it will find it can perform operations much faster on the former. This is in fact a very powerful concept and hence depending on the processor and store combination users can define limitless number of EI patterns in synapse that could meet different runtime requirements and SLA's. Synapse by default support two processors which are scheduled message processor and sampling processor.
Synapse Configuration Files
All the XML files pertaining to the Synapse configuration are available in the repository/conf/synapse-config directory of the Synapse installation. This file hierarchy consists of two files named synapse.xml and registry.xml. In addition to that, following sub-directories can be found in the synapse-config directory.
- api
- endpoints
- events
- local-entries
- message-processors
- message-stores
- priority-executors
- proxy-services
- sequences
- tasks
- templates
Each of these sub-directories can contain zero or more configuration items. For an example the 'endpoints' directory may contain zero or more endpoint definitions and the 'sequences' directory may contain zero or more sequence definitions. The registry adapter is defined in the top level registry.xml file. The synapse.xml file is there mainly for backward compatibility reasons. It can be used to define any type of configuration items. One may define few endpoints in the 'endpoints' directory and a few endpoints in the synapse.xml file. However it is recommended to stick to a single, consistent way of defining configuration elements. So you should either define everything in synapse.xml file, or not use it at all.
The following tree diagram shows the high-level view of the resulting file hierarchy.
Configuration Syntax
Synapse ESB is configured using an XML based configuration language. This is a Domain Specific Language (DSL) created and maintained by the Synapse community. The language is designed to be simple, intuitive and easy to learn. All XML elements (tags) in this language must be namespace qualified with the namespace URL http://ws.apache.org/ns/synapse.
As stated earlier, the synapse.xml file can be used to define all kinds of artifacts. All these different configuration items should be wrapped in a top level 'definitions' element. A configuration defined in the synapse.xml file looks like this at the high level.
The registry adapter definition is defined under the <registry> element. Similarly <endpoint>, <sequence>, <proxy>, <localEntry>, <eventSource and <executor> elements are used to define other functional components.
As pointed out earlier, the synapse.xml file is there in the synapse-config directory for backwards compatibility reasons. Any artifact defined in this file can be defined separately in its own XML file. The registry can be defined in the registry.xml and other artifacts can be defined in the corresponding sub-directories of the synapse-config directory. However the XML syntax used to configure these artifacts are always the same. Next few sections of this document explains the XML syntax for defining various types of components in the Synapse configuration.
Registry Configuration
The <registry> element is used to define the registry adapter used by the Synapse runtime. The registry provider specifies an implementation class for the registry being used, and optionally a number of configuration parameters as may be required by the particular registry implementation. An outline configuration is given below.
Registry entries loaded from a remote registry may be cached as governed by the registry, and reloaded after the cache periods expires if a newer version is found. Hence it is possible to define configuration elements such as (dynamic) sequences and endpoints, as well as resources such as XSLT's, scripts or XSDs in the registry, and update the configuration as these are allowed to dynamically change over time.
Synapse ships with a built-in URL based registry implementation called the 'SimpleURLRegistry' and this can be configured as follows:
The 'root' parameter specifies the root URL of the registry for loaded resources. The SimpleURLRegistry keys are path fragments, that when combined with the root prefix would form the full URL for the referenced resource. The 'cachableDuration' parameter specifies the number of milliseconds for which resources loaded from the registry should be cached. More advanced registry implementations allows different cachable durations to be specified for different resources, or mark some resources as never expires. (e.g. Check the WSO2 ESB implementation based on Apache Synapse)
Local Entry (Local Registry) Configuration
Local entries provide a convenient way to import various external configuration artifacts into the Synapse runtime. This includes WSDLs, policies, XSLT files, and scripts. Local entry definitions are parsed at server startup and the referenced configurations are loaded to the memory where they will remain until the server is shut down. Other functional components such as sequences, endpoints and proxy services can refer these locally defined in-memory configuration elements by using the local entry keys.
The <localEntry> element is used to declare registry entries that are local to the Synapse instance. Following syntax is used to define a local entry in the Synapse configuration.
A local entry may contain static text or static XML specified as inline content. Following examples show how such static content can be included in local entry definitions.
Note the validate_schema local entry which wraps some static XML schema content. A mediator such as the validate mediator can refer this local entry to load its XML schema definition.
A local entry may also point to a remote URL (specified using the 'src' attribute) from which the contents can be loaded. This way the user does not have to specify all external configurations in the Synapse configuration itself. The required artifacts can be kept on the file system or hosted on a web server from where Synapse can fetch them using a local entry definition. Following example shows how a local entry is configured to load an XSLT file from the local file system.
It is important to note that Synapse loads the local entry contents only during server start up (even when they are defined with a remote URL). Therefore any changes done on the remote artifacts will not reflect on Synapse until the server is restarted. This is in contrast to the behavior with remote registry where Synapse reloads configuration artifacts as soon as the cache period expires.
Sequence Configuration
As explained earlier a sequence resembles a message flow in Synapse and consists of an array of mediators. The <sequence> element is used to define a sequence in the Synapse configuration. Sequences can be defined with names so they can be reused across the Synapse configuration. The sequences named 'main' and 'fault' have special significance in a Synapse configuration. The 'main' sequence handles any message that is accepted for 'Message Mediation'. The 'fault' sequence is invoked if Synapse encounters a fault, and a custom fault handler is not specified for the sequence via its 'onError' attribute. If the 'main' or 'fault' sequences are not defined locally or not found in the Registry, Synapse auto generates suitable defaults at initialization.
A Dynamic Sequence may be defined by specifying a key reference to a registry entry. As the remote registry entry changes, the sequence will dynamically be updated according to the specified cache duration and expiration. If tracing is enabled on a sequence, all messages being processed through the sequence would write tracing information through each mediation step to the 'trace.log' file configured via the log4j.properties configuration.
The syntax outline of a sequence definition is given below.
The 'onError' attribute can be used to define a custom error handler sequence. Statistics collection can be activated by setting the 'statistics' attribute to 'enable' on the sequence. In this mode the sequence will keep track of the number of messages processed and their processing times. This statistical information can then be retrieved through the Synapse statistics API.
All the immediate child elements of the sequence element must be valid mediators. Following example shows a sequence configuration which consists of three child mediators.
Sequences can also hand over messages to other sequences. In this sense a sequence is analogous to a procedure in a larger program. In many programming languages procedures can invoke other procedures. See the following example sequence configuration.
Note how the message is handed to a sequence named 'other_sequence' using the 'sequence' element. The 'key' attribute could point to another named sequence, a local entry or a remote registry entry.
Endpoint Configuration
An <endpoint> element defines a destination for an outgoing message. There are several types of endpoints that can be defined in a Synapse configuration.
- Address endpoint
- WSDL endpoint
- Load balance endpoint
- Fail-over endpoint
- Default endpoint
- Recipient list endpoint
Configuration syntax and runtime semantics of these endpoint types differ from each other. However the high level configuration syntax of an endpoint definition takes the following form.
Note how the endpoint definitions always start with an 'endpoint' element. The immediate child element of this top level 'endpoint' element determines the type of the endpoint. All above endpoint types can have a 'name' attribute, and such named endpoints can be referred by other endpoints, through the key attribute. For example if there is an endpoint named 'foo', the following endpoint can be used in any place, where 'foo' has to be used.
This provides a simple mechanism for reusing endpoint definitions within a Synapse configuration.
The 'trace' attribute turns on detailed trace information for messages being sent to the endpoint. These will be available in the 'trace.log' file configured via the log4j.properties file.
Address Endpoint
Address endpoint is an endpoint defined by specifying the EPR and other attributes of the endpoint directly in the configuration. The 'uri' attribute of the address element contains the EPR of the target endpoint. Message format for the endpoint and the method to optimize attachments can be specified in the 'format' and 'optimize' attributes respectively. Security policies for the endpoint can be specified in the policy attribute of the 'enableSec' element. WS-Addressing can be engaged for the messages sent to the endpoint by using the 'enableAddressing' element.
The 'timeout' element of the endpoint configuration is used to set a specific socket timeout for the endpoint. By default this is set to 1 minute (60 seconds). When integrating with back-end services which take longer to respond the timeout duration should be increased accordingly. The 'responseAction' element states the action that should be taken in case a response is received after the timeout period has elapsed. Synapse can either 'discard' the delayed response or inject it into a 'fault' handler.
A Synapse endpoint is a state machine. At any given point in time it could be in one of four states - Active, Timeout, Suspended and Switched Off. How and when an endpoint changes its state is configurable through the Synapse configuration. An endpoint in suspended or switched off states cannot be used to send messages. Such an attempt would generate a runtime error.
By default an endpoint is in the 'Active' state. The endpoint will continue to forward requests as long as its in this state. If an active endpoint encounters an error while trying to send a message out (eg: a connection failure), the endpoint may get pushed into the 'Timeout' state or the 'Suspended' state. Generally most errors will put the endpoint straight into the 'Suspended' state. Connection timeouts (error code 101504) and connection closed errors (101505) are the only errors that will not directly suspend an endpoint. Using the 'errorCodes' element in the 'suspendOnFailure' configuration one can explicitly define the errors for which the endpoint should be suspended. Similarly the 'errorCodes' element in the 'markForSuspension' configuration can be used to define the errors for which the endpoint should be pushed into the 'Timeout' state.
Endpoints in 'Timeout' state can be used to send messages. But any consecutive errors while in this state can push the endpoint into the 'Suspended' state. The number of consecutive errors that can suspend the endpoint can be configured using the 'retriesBeforeSuspension' element in the 'markForSuspension' configuration. The 'retryDelay' is used to specify a duration for which an endpoint will not be available for immediate use after moving it to the 'Timeout' state. This duration should be specified in milliseconds.
An endpoint in 'Suspended' state cannot be used to send messages. However the suspension is only temporary. The suspend duration can be configured using the 'initialDuration' element. When this time period expires a suspended endpoint becomes available for use again. However any recurring errors can put the endpoint back in the 'Suspended' state. Such consecutive suspensions can also progressively increase the suspend duration of the endpoint as configured by the 'progressionFactor' element. But the suspend duration will never exceed the period configured in the 'maximumDuration' element. Note that both 'initialDuration' and 'maximumDuration' should be specified in milliseconds.
Some example address endpoint configurations are given below. Note how the communication protocol is used as a suffix to indicate the outgoing transport.
| Transport | Sample address |
|---|---|
| HTTP | http://localhost:9000/services/SimpleStockQuoteService |
| JMS | jms:/SimpleStockQuoteService? transport.jms.ConnectionFactoryJNDIName=QueueConnectionFactory& java.naming.factory.initial=org.apache.activemq.jndi.ActiveMQInitialContextFactory& java.naming.provider.url=tcp://localhost:61616& transport.jms.DestinationType=topic |
| mailto:guest@host | |
| VFS | vfs:file:///home/user/directory |
| vfs:file:///home/user/file | |
| vfs:ftp://guest:guest@localhost/directory?vfs.passive=true |
Default Endpoint
Default endpoint is an endpoint defined for adding QoS and other configurations to the endpoint which is resolved from the 'To' address of the message context. All the configurations such as message format for the endpoint, the method to optimize attachments, and security policies for the endpoint can be specified as in the case of Address Endpoint. This endpoint differs from the address endpoint only in the 'uri' attribute which will not be present in this endpoint. Following section describes the configuration of a default endpoint.
WSDL Endpoint
WSDL endpoint is an endpoint definition based on a specified WSDL document. The WSDL document can be specified either as a URI or as an inline definition within the configuration. The service and port name containing the target EPR has to be specified with the 'service' and 'port' (or 'endpoint') attributes respectively. Elements like 'enableSec', 'enableAddressing', 'suspendOnFailure' and 'timeout' are same as for an Address endpoint.
Load Balance Endpoint
A Load balanced endpoint distributes the messages (load) among a set of listed endpoints or static members by evaluating the load balancing policy and any other relevant parameters. The policy attribute of the load balance element specifies the load balance policy (algorithm) to be used for selecting the target endpoint or static member. Currently only the roundRobin policy is supported. The 'failover' attribute determines if the next endpoint or static member should be selected once the currently selected endpoint or static member has failed, and defaults to true. The set of endpoints or static members amongst which the load has to be distributed can be listed under the 'loadBalance' element. These endpoints can belong to any endpoint type mentioned in this document. For example, failover endpoints can be listed inside the load balance endpoint to load balance between failover groups etc. The 'loadbalance' element cannot have both 'endpoint' and 'member' child elements in the same configuration. In the case of the 'member' child element, the 'hostName', 'httpPort' and/or 'httpsPort' attributes should be specified.
The optional 'session' element makes the endpoint a session affinity based load balancing endpoint. If it is specified, sessions are bound to endpoints in the first message and all successive messages for those sessions are directed to their associated endpoints. Currently there are two types of sessions supported in session aware load balancing. Namely HTTP transport based session which identifies the sessions based on http cookies and the client session which identifies the session by looking at a SOAP header sent by the client with the QName '{http://ws.apache.org/ns/synapse}ClientID'. The 'failover' attribute mentioned above is not applicable for session affinity based endpoints and it is always considered as set to false. If it is required to have failover behavior in session affinity based load balance endpoints, failover endpoints should be listed as the target endpoints.
Dynamic Load Balance Endpoint
This is a special variation of the load balance endpoint where instead of having to specify the child endpoints explicitly, the endpoint automatically discovers the child endpoints available for load balancing. These child endpoints will be discovered using the 'membershipHandler' class. Generally, this class will use a group communication mechanism to discover the application members. The 'class' attribute of the 'membershipHandler' element should be an implementation of org.apache.synapse.core.LoadBalanceMembershipHandler. The 'membershipHandler' specific properties can be specified using the 'property' elements. The 'policy' attribute of the 'dynamicLoadbalance' element specifies the load balance policy (algorithm) to be used for selecting the next member to which the message has to be forwarded. Currently only the 'roundRobin' policy is supported. 'The failover' attribute determines if the next member should be selected once the currently selected member has failed, and defaults to true.
Currently Synapse ships with one implementation of the LoadBalanceMembershipHandler interface. This class is named 'Axis2LoadBalanceMembershipHandler' and its usage is demonstrated in sample 57.
Fail-Over Endpoint
Failover endpoints send messages to the listed endpoints with the following failover behavior. At the start, the first listed endpoint is selected as the primary and all other endpoints are treated as backups. Incoming messages are always sent only to the primary endpoint. If the primary endpoint fails, next active endpoint is selected as the primary and failed endpoint is marked as inactive. Thus it sends messages successfully as long as there is at least one active endpoint among the listed endpoints.
When a previously failed endpoint becomes available again, it will assume its position as the primary endpoint and the traffic will be routed to that endpoint. It is possible to disable this behavior by setting the 'dynamic' attribute to false.
Recipient List Endpoint
A recipient list endpoint can be used to send a single message to a list of recipients (child endpoints). This is used to implement the well-known integration pattern named 'recipient list'. The same functionality can be achieved using the 'clone' mediator, but the recipient list provides a more natural and intuitive way of implementing such a scenario. Configuration of the recipient list endpoint takes the following general form.
A recipient list can be named by setting the 'name' attribute on the 'recipientList' element. Similar to a load balance endpoint, the recipient list endpoint also wraps a set of endpoint definitions or a set of member definitions. At runtime messages will be sent to all the child endpoints or members.
Proxy Service Configuration
A <proxy> element is used to define a Synapse Proxy service.
A proxy service is created and exposed on the specified transports through the underlying Axis2 engine, exposing service EPRs as per the standard Axis2 conventions (ie based on the service name). Note that currently Axis2 does not allow custom URI's to be set for services on some transports such as http/s. A proxy service could be exposed over all enabled Axis2 transports such as http, https, JMS, Mail and File etc. or on a subset of these as specified by the optional 'transports' attribute. By default, if this attribute is not specified, Synapse will attempt to expose the proxy service on all enabled transports.
In a clustered setup it might be required to deploy a particular proxy service on a subset of the available nodes. This can be achieved using the 'pinnedServers' attribute. This attribute takes a list of server names. At server startup Synapse will check whether the name of the current host matches any of the names given in this attribute and only deploy the proxy service if a match is found. The server host name is picked from the system property 'SynapseServerName', failing which the hostname of the machine would be used or default to 'localhost'. User can specify a more meaningful name to a Synapse server instance by starting the server using the following command.
If Synapse is started as a daemon or a service, the above setting should be specified in the wrapper.conf file.
By default when a proxy service is created it is added to an Axis service group which has the same name as the proxy service. With the 'serviceGroup' attribute this behavior can be further configured. A custom Axis service group can be specified for a proxy service using the 'serviceGroup' attribute. This way multiple proxy services can be grouped together at Axis2 level thus greatly simplifying service management tasks.
Each service could define the target for received messages as a named sequence or a direct endpoint. Either target inSequence or endpoint is required for the proxy configuration, and a target outSequence defines how responses should be handled. Any WS-Policies provided would apply as service level policies, and any service parameters could be passed into the proxy service's AxisService instance using the 'parameter' elements (e.g. the JMS destination etc). If the proxy service should enable WS-Reliable Messaging or Security, the appropriate modules should be engaged, and specified service level policies will apply. To engage the required modules, one may use the 'enableSec', and 'enableAddressing' elements.
A dynamic proxy may be defined by specifying the properties of the proxy as dynamic entries by referring them with the key. For example one could specify the inSequence or endpoint with a remote key, without defining it in the local configuration. As the remote registry entry changes, the properties of the proxy will dynamically be updated accordingly. (Note: proxy service definition itself cannot be specified to be dynamic; i.e <proxy key="string"/> is wrong)
A WSDL for the proxy service can be published using the 'publishWSDL' element. The WSDL document can be loaded from the registry by specifying the 'key' attribute or from any other location by specifying the 'uri' attribute. Alternatively the WSDL can be provided inline as a child element of the 'publishWSDL' element. Artifacts (schemas or other WSDL documents) imported by the WSDL can be resolved from the registry by specifying appropriate 'resource' elements.
In this example the WSDL is retrieved from the registry using the key 'my.wsdl'. It imports another WSDL from location 'http://www.standards.org/standard.wsdl'. Instead of loading it from this location, Synapse will retrieve the imported WSDL from the registry entry 'standard.wsdl'.
Some well-known parameters that are useful when writing complex proxy services are listed below. These can be included in a proxy configuration using 'parameter' tags.
| Parameter | Value | Default | Description |
|---|---|---|---|
| useOriginalwsdl | true|false | false | Use the given WSDL instead of generating the WSDL. |
| modifyUserWSDLPortAddress | true|false | true | (Effective only with useOriginalwsdl=true) If true (default) modify the port addresses to current host. |
| showAbsoluteSchemaURL | true|false | false | Show the absolute path of the referred schemas of the WSDL without showing the relative paths. |
Following table lists some transport specific parameters that can be passed into proxy service configurations.
| Transport | Require | Parameter | Description |
|---|---|---|---|
| JMS | Optional | transport.jms.ConnectionFactory | The JMS connection factory definition (from axis2.xml) to be used to listen for messages for this service |
| Optional | transport.jms.Destination | The JMS destination name (Defaults to a Queue with the service name) | |
| Optional | transport.jms.DestinationType | The JMS destination type. Accept values 'queue' or 'topic' (default: queue) | |
| Optional | transport.jms.ReplyDestination | The destination where a reply will be posted | |
| Optional | transport.jms.Wrapper | The wrapper element for the JMS message |
Scheduled Task Configuration
A <task> element is used to define a Synapse task (aka startup).
A task is created and scheduled to run at specified time intervals or as specified by the cron expression. The 'class' attribute specifies the actual task implementation class (which must implement org.apache.synapse.task.Task interface) to be executed at the specified interval/s, and name specifies an identifier for the scheduled task.
Fields in the task class can be set using properties provided as string literals or XML fragments. For example, if the task implementation class has a field named 'version' with a corresponding setter method, the configuration value which will be assigned to this field before running the task can be specified using a property with the name 'version'.
There are three different trigger mechanisms to schedule tasks. A simple trigger is specified with a 'count' and an 'interval', implying that the task will run a 'count' number of times at specified intervals. A trigger may also be specified as a cron trigger using a cron expression. A one-time trigger is specified using the 'once' attribute in the definition and could be specified as true in which case the task will be executed only once just after the initialization of Synapse.
In clustered deployments sometimes it would be necessary to deploy a particular task in a selected set of nodes. This can be achieved using the optional 'pinnedServers' attribute. A list of server names or host names can be specified in this attribute. At server startup, Synapse will match the current server name or the host name with the values specified in this attribute to see whether the task should be initialized or not.
Template Configuration
As explained earlier templates in synapse are defined in two flavors; sequence and endpoint templates. The configuration, syntax forms and semantics of these are explained in the following section.
A sequence template consist of two parts. As in any kind of a function, it has a parameter set definition (argument list) and a function body definition. An important difference is sequence template parameters are not typed (typically these are string parameters, but can be of any type which is determined at runtime). Also function body is a typical esb flow or a sequence.
The syntax outline of a sequence template definition is given below.
A sequence template is a top level element defined with the 'name' attribute in Synapse configuration. Both endpoint and sequence templates start with a 'template' element. Parameters (defined by <parameter> elements) are the inputs supported by a sequence template. These sequence template parameters can be referred by any xpath expression defined within the in-lined sequence. For example parameter named 'foo' can be referred by a property mediator (defined inside the in-line sequence of the template) in following ways.
Note the scope variable used in the XPath expression. We use 'function' scope or '$func' to refer to template parameters.
Invoking a sequence template can be done with a mediator named 'call-template' by passing parameter values. The syntax outline of a call template mediator definition is given below.
The 'call-template' mediator should define a target template it should be invoking, with 'target' attribute.
The 'with-param' element is used to parse parameter values to a target sequence template. Note that parameter names has to be exact matches to the names specified in the target template. Parameter elements can contain three types of parameterized values. xpath values are passed in within curly braces ({}) for value attribute.
Endpoint templates are similar to the sequence templates in definition. Unlike sequence templates, endpoint templates are always parameterized using '$' prefixed values (NOT xpath expressions). Users can parameterize endpoint configuration elements with these '$' prefixed values. An example is shown below.
The syntax outline of a endpoint template definition is given below.
As described earlier template endpoint is the artifact that makes a template of an endpoint type into a concrete endpoint. In other words an endpoint template would be useless without a template endpoint referring to it. This is semantically similar to the relationship between a sequence template and a 'call-template' mediator.
The syntax outline of a template endpoint definition is as following..
Template endpoint defines parameter values that can parameterize an endpoint. The 'template' attribute points to a target endpoint template.
As in the case of sequence template, note that parameter names has to be exact match to the names specified in target endpoint template.
Event Source Configuration
Event sources enable the user to run Synapse in the eventing mode of operation. Synapse can act as an event source as well as an event broker. An event source is defined using the <eventSource> configuration element.
Once an event source is deployed in Synapse, it will provide a service URL (EPR) to which clients can send WS-Eventing subscription requests. Clients can subscribe, unsubscribe and renew subscriptions by sending messages to this EPR. The subscription manager configured inside the event source will be responsible for storing and managing the subscriptions. The 'class' attribute of the 'subscriptionManager' element should point to the Java class which provides this subscription management functionality. Synapse ships with an in-memory subscription manager which keeps and manages all subscriptions in memory.
Any additional parameters required to configure the subscription manager implementation can be specified using the 'parameter' elements.
API Configuration
APIs provide a flexible and powerful approach for defining full fledged REST APIs in Synapse. An API definition starts with the <api> element.
Each API definition must be uniquely named using the 'name' attribute. The 'context' attribute is used to define the URL context at which the REST API will be anchored (eg: /ws, /foo/bar, /soap). The API will only receive requests that fall in the specified URL context. In addition to that an API could be bound to a particular host and a port using the 'hostname' and 'port' attributes. The 'transport' attribute can be used to restrict the API to process either HTTP messages or HTTPS messages only.
An API must also contain one or more resources. Resources define how messages are processed and mediated by the API. A resource can be associated with a set of HTTP methods using the 'methods' attribute. This attribute can support a single method name (eg: GET) or a space separated list of methods (eg: GET PUT DELETE). The 'url-mapping' and 'uri-template' attributes can be used to specify the type of URL requests that should be handled by any particular resource. The 'url-mapping' attribute accepts any Java servlet style URL mapping (eg: /test/*, *.jsp). The 'uri-template' attribute accepts valid RFC6570 style expressions (eg: /orders/{orderId}). A resource can also refer other sequences using the 'inSequence', 'outSequence' and 'faultSequence' attributes. Alternatively these mediation sequences can be defined inline with the resource using 'inSequence', 'outSequence' and 'faultSequence' tags.
An API can also optionally define a set of handlers. These handlers are invoked for each incoming API request, before they are dispatched to the appropriate resources. The 'class' attribute on the 'handler' elements should contain the ful qualified names of the handler implementation classes.
Priority Executor Configuration
The priority executor configuration syntax takes the following general form.
A priority executor consists of a thread pool and a set of queues for different priority levels. Queues can be either bounded on unbounded in terms of capacity. Each executor must define at least two queues. By default queues are unbounded. By specifying the attribute 'size' they can be configured to have a limited capacity. The 'priority' attribute specifies the priority level associated with a particular queue. As explained earlier, higher the level, higher the priority the messages will get.
The next queue algorithm is used to determine the next message processed. By default Synapse uses a built-in priority queueing algorithm for this purpose. If required a custom algorithm can be used by specifying the 'nextQueue' algorithm on the 'queues' element.
The 'threads' element is used to configure the underlying thread pool. The 'core' and 'max' attributes are used to specify the initial size and the maximum size of the thread pool. A keep-alive time duration can be specified for idling threads using the 'keep-alive' attribute where the duration is configured in seconds. If not specified a default keep-alive duration of 5 seconds will be used.
In order to process messages through a priority executor one must use the 'enqueue' mediator. This mediator can be used in a sequence or a proxy service to get all requests processed through a pre-configured priority executor.
For best results it's recommended to dispatch messages into priority executors straight from the transport level. This can be achieved by adding an additional parameter to the NHTTP transport configuration in the axis2.xml file of Synapse.
The parameter should point to a separate XML configuration which defines the priority configuration.
Message Stores and Processors Configuration
Both Message Stores and processors are top level configuration of synapse. Following section tries to describe some of the syntax of the message store/processors configurations.
The syntax outline of a message store definition is given below.
The 'class' attribute value is the fully qualified class name of the underlying message store implementation. There can be many message store implementations.Users can write their own message store implementation and use it. Parameters section is used to configure the parameters that is needed by underlying message store implementation.
The syntax outline of a message processor definition is given below.
The 'class' attribute value is the fully qualified class name of the underlying message processor implementation. There are two message processor implementations shipped by default. There can be many message processor implementations.Users can write their own message processor implementation and use it. Similar to message stores ,parameters section here as well is used to configure the parameters that is needed by underlying message processor implementation
As mentioned earlier, there are several message store/processor implementations shipped by default. However if users wants to extend these following interfaces are available.